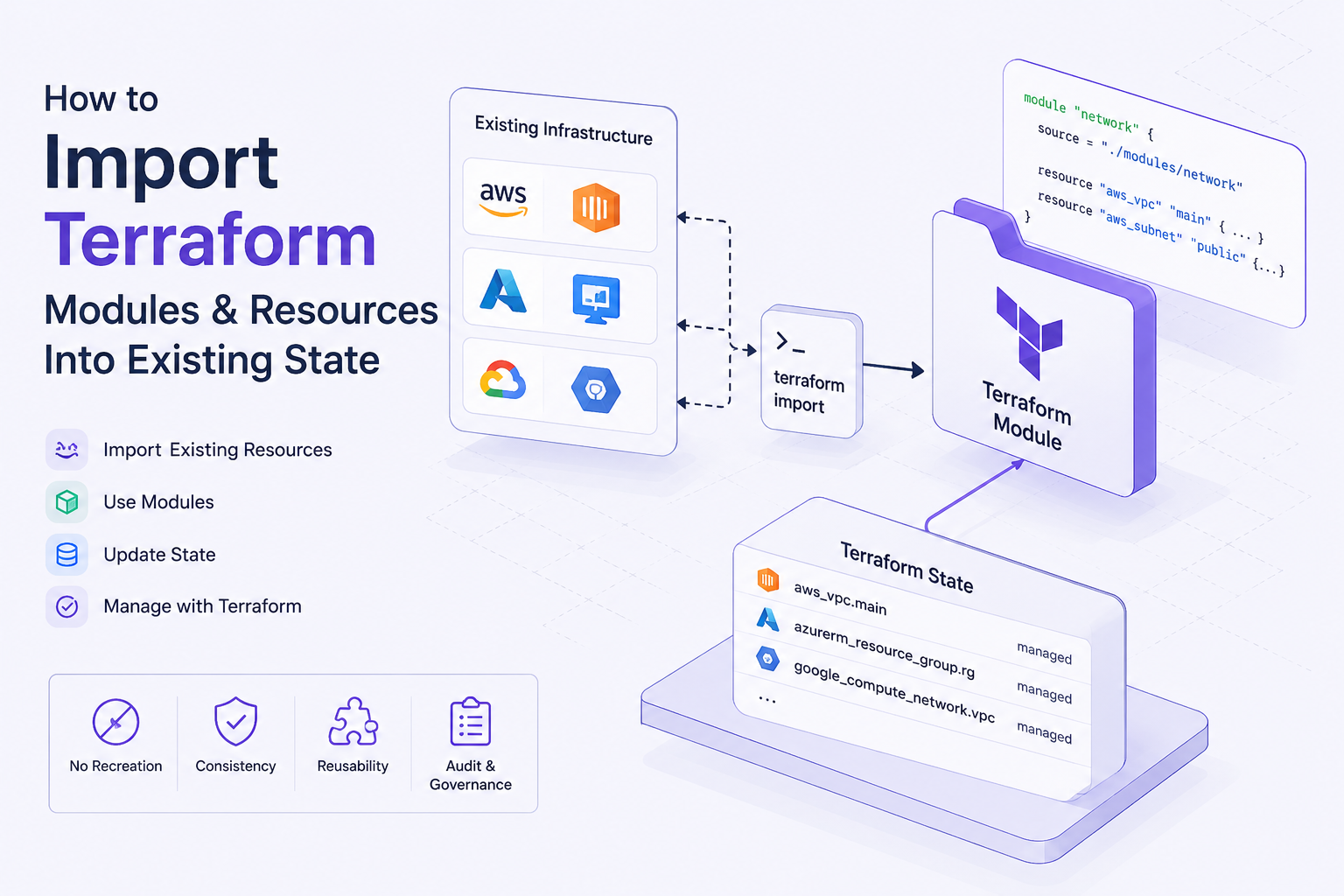
IaC Guides & Best Practices | env zero
Terraform Security Scanning: Tools and CI/CD Integration Guide
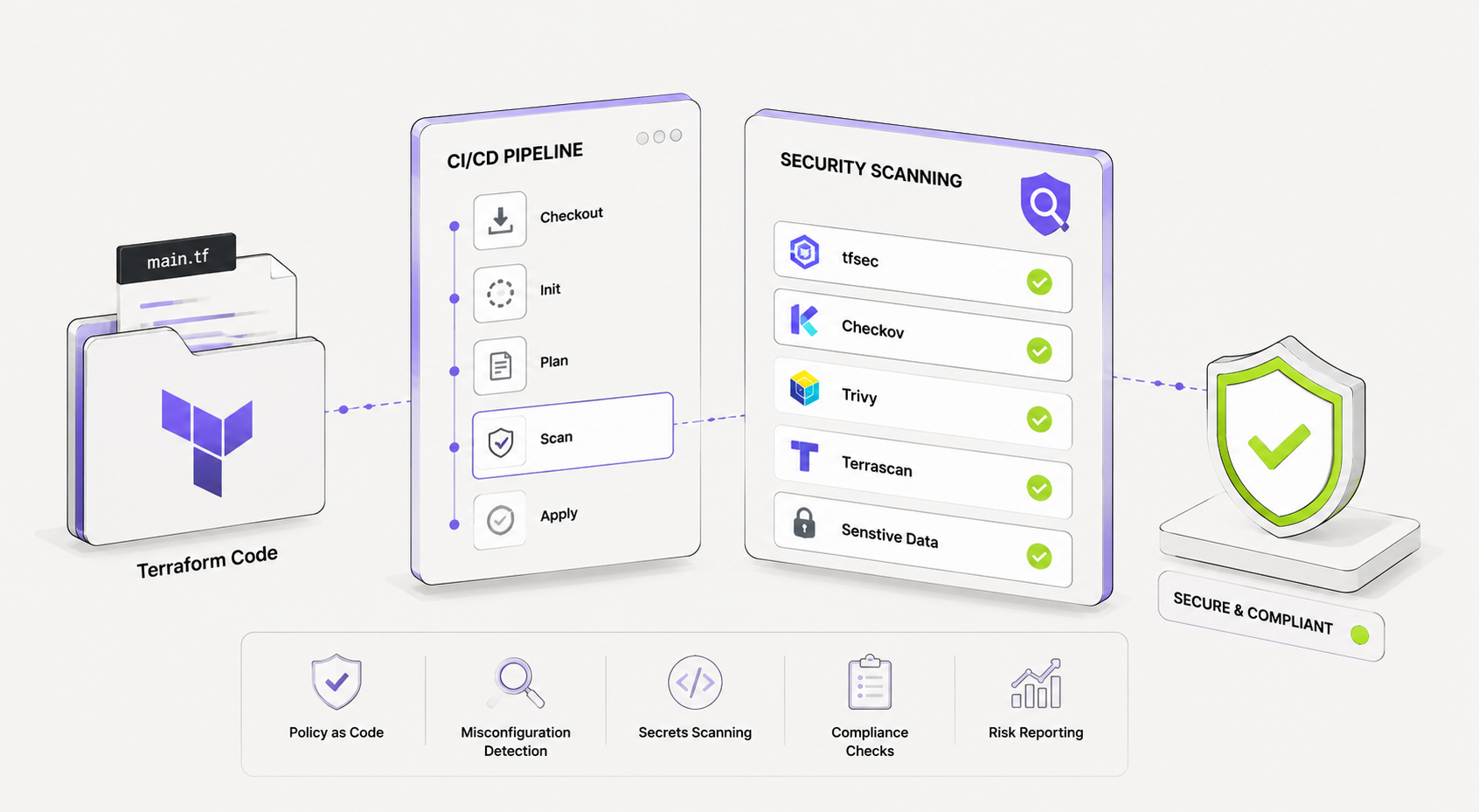
Deploying infrastructure code without security scanning is similar to releasing application code without testing. Common cloud security risks such as publicly exposed storage buckets, unencrypted databases, and overly permissive IAM policies can often be detected and fixed before deployment. Terraform security scanning helps teams identify these issues early, reducing the risk of security incidents and compliance violations. This guide explores the leading Terraform security scanning tools, demonstrates how to integrate them into GitHub Actions and GitLab CI pipelines, explains policy enforcement with Open Policy Agent (OPA), and highlights practical approaches for prioritizing and remediating critical security findings.